AVL 树,红黑树,B 树,B + 树,Trie 树都分别应用在哪些现实场景中?
AVL 树: 最早的平衡二叉树之一。应用相对其他数据结构比较少。windows 对进程地址空间的管理用到了 AVL 树。红黑树: 平衡二叉树,广泛用在 C++ 的 STL 中。如 map 和 set 都是用红黑树实现的。B/B + 树: 用在磁盘文件组织 数据索引和数据库索引。Trie 树 (字典树): 用在统计和排序大量字符串,如自动机。
AVL 树是平衡二叉搜索树的鼻祖,它的平衡度也最好,左右高度差可以保证在「-1,0,1」,基于它的平衡性,它的查询时间复杂度可以保证是 O(log n)。但每个节点要额外保存一个平衡值,或者说是高度差。这种树是二叉树的经典应用,现在最主要是出现在教科书中。AVL 的平衡算法比较麻烦,需要左右两种 rotate 交替使用,需要分四种情况,是数据结构课的最理想课后作业之一。这里要重点强调,AVL 插入新节点所需要的最大旋转次数是常数,再说一遍,是常数,不要为这个再来回复或者私信我了。这个也有证明,不需要一直旋转到根节点。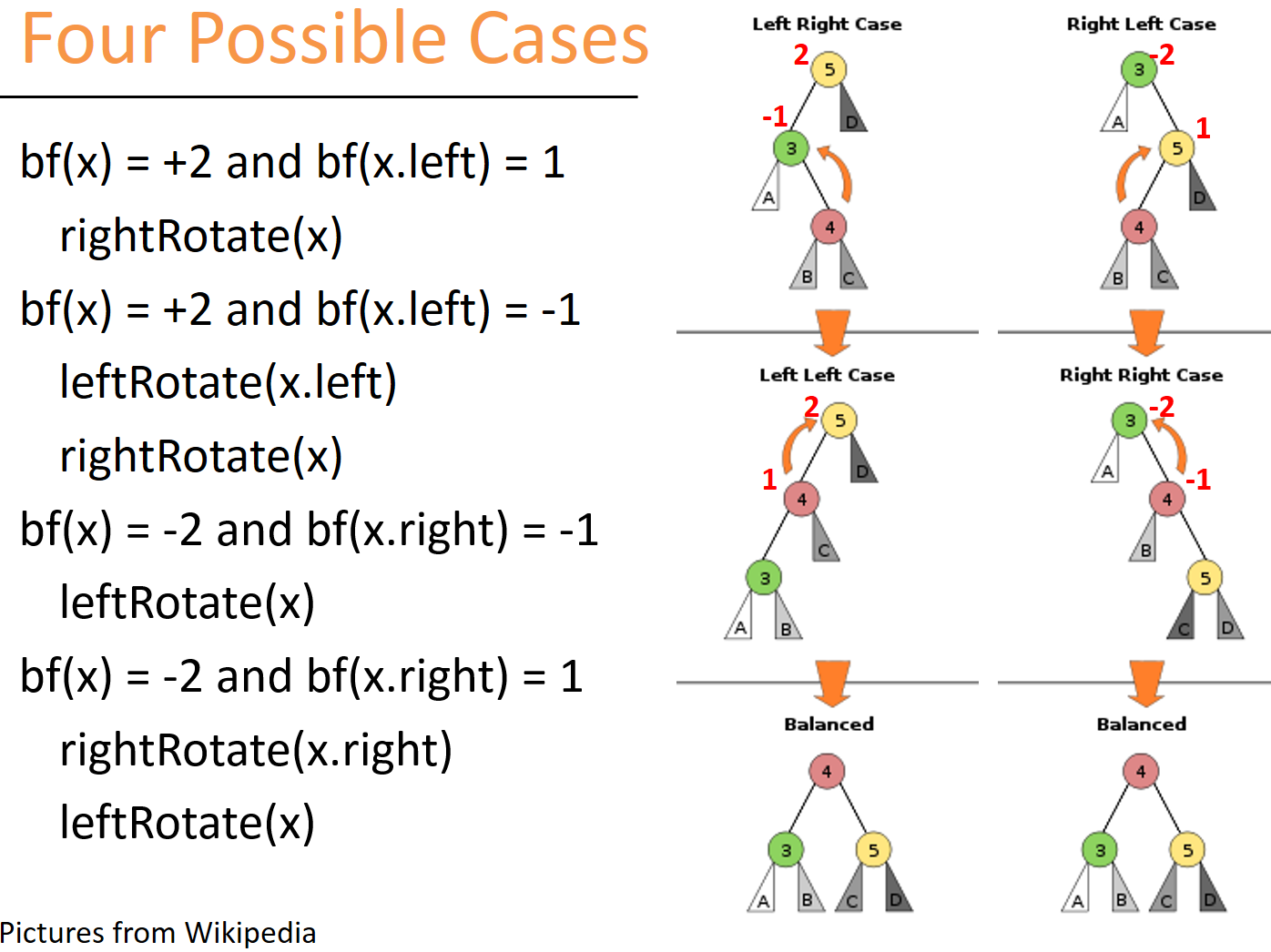 红黑树一样也是平衡二叉搜索树,也是工业界最主要使用的二叉搜索平衡树。但平衡度红黑树没 AVL 那么好。也就是说,如果从高度差来说,红黑树是大于 AVL 的,其实也就代表着它的实际查询时间 (最坏情况) 略逊于 AVL 的。数学证明红黑树的最大深度是
红黑树一样也是平衡二叉搜索树,也是工业界最主要使用的二叉搜索平衡树。但平衡度红黑树没 AVL 那么好。也就是说,如果从高度差来说,红黑树是大于 AVL 的,其实也就代表着它的实际查询时间 (最坏情况) 略逊于 AVL 的。数学证明红黑树的最大深度是 , 其实最差情况它从根到叶子的最长路可以是最短路的两倍,但也不是很差,所以它的查询时间复杂度也是 O(log n)。从实现角度来说,保存红黑状态,每个节点只需要一位二进制,也就是一个 bit(有些做法,可以把这个 bit 塞到其他地方,就可以不占用额外空间了)。可 AVL 每个节点需要额外存储一个平衡值(数)(按照评论中大神韦易笑的说法,avl 的平衡值可以用两个 bit 来存储,然后塞到指针里,惊才绝艳的搞法。当然指针少两位会有什么问题,我就不多想了,你去找他,他有个很好的 avl 实现)。所以(这里不能用所以,因为谁知道真实原因是啥),一般工业界把红黑树作为一种更通用的平衡搜索数来用,Java 用它来实现 TreeMap, C++ 的 std::set/map/multimap 等等。以上都是二叉(binary)树,其实没有太多实质差别。他们的实现都比较复杂,如果做得不好会带来性能的隐患,所以强烈建议入行不足 10 年的朋友尽量使用系统中的已有默认实现,不管是 avl 还是红黑树,这两个有什么就用什么,千万别自己写代码,能写也别写,留个坑给别人不合适。二叉平衡搜索树的问题在于每次插入和删除都有很大可能需要进行重新平衡,数据就要不停的搬来搬去,在内存中这问题不是特别大,可如果在磁盘中,这个开销可能就大了。有兴趣的朋友还可以看看 2-3-4 tree,它等价于红黑树,可以互相转换。它每个节点可以最多有四个孩子,重新平衡操作的次数稍稍少了一点点。以上这些树绝大多数应用都是作为内存中的数据结构。B/B+ 树就是 N 叉(N-ary)平衡树了,每个节点可以有更多的孩子,新的值可以插在已有的节点里,而不需要改变树的高度,从而大量减少重新平衡和数据迁移的次数,这非常适合做数据库索引这种需要持久化在磁盘,同时需要大量查询和插入操作的应用。以上几种树都是有序的,如果你采用合适的算法遍历整个数,可以得到一个有序的列表。这也是为什么如果有数据库索引的情况下,你 order by 你索引的值,就会速度特别快,因为它并没有给你真的排序,只是遍历树而已。Trie 并不是平衡树,也不一定非要有序。它主要用于前缀匹配,比如字符串,比如说 ip 地址,如果字符串长度是固定或者说有限的,那么 Trie 的深度是可控制的,你可以得到很好的搜索效果,而且插入新数据后不用平衡。不过 Trie 不像 B-tree 通用性那么强,你需要针对你自己的实际应用来设计你自己的 Trie,比如说你做个字典应用,是用 26 个字母,还是用 unicode 来前缀匹配?如果是 ip 地址搜索,是用二进制来前缀拼配,还是八进制来匹配?

韦易笑
楼上楼下 AVL 被批的很惨,给 AVL 树平反昭雪,今天优化了一下我之前的 AVL 树,总体跑的和 linux 的 rbtree 一样快了: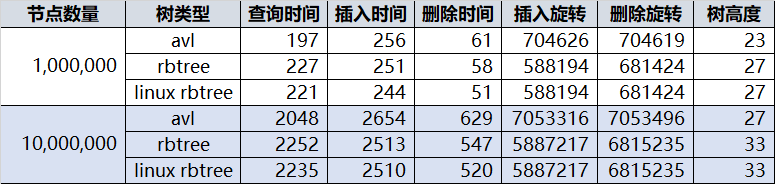 他们都比 std::map 快很多(即便使用动态内存分配,为每个新插入节点临时分配个新内存)。其他 AVL/RBTREE 评测也有类似的结论,见:STL AVL Map
他们都比 std::map 快很多(即便使用动态内存分配,为每个新插入节点临时分配个新内存)。其他 AVL/RBTREE 评测也有类似的结论,见:STL AVL Map
谣言 1:RBTREE 的平均统计性能比 AVL 好统计下来一千万个节点插入 AVL 共旋转 7053316 次(先左后右算两次),RBTREE 共旋转 5887217 次,RBTREE 看起来少是吧?应该很快?但是别忘了 RBTREE 再平衡的操作除了旋转外还有再着色,每次再平衡噼里啪啦的改一片颜色,父亲节点,叔叔,祖父,兄弟节点都要访问一圈,这些都是代价,再者平均树高比 AVL 高也成为各项操作的成本。
谣言 2:RBTREE 一般情况只比 AVL 高一两层,这个代价忽略不计纯粹谣言,随便随机一下,一百万个节点的 RBTREE 树高 27,和一千万个节点的 AVL 树相同,而一千万个节点的 RBTREE 树高 33,比 AVL 多了 6 层,这还不是最坏情况,最坏情况 AVL 只有 1.440 * log(n + 2) - 0.328, 而 RBTREE 是 2 * log(n + 1),也就是说同样 100 万个节点,AVL 最坏情况是 28 层,rbtree 最坏可以到 39 层。
谣言 3:AVL 树删除节点是需要回溯到根节点我以前也是这么写 AVL 树的,后来发现根据 AVL 的定义,可以做出两个推论,再平衡向上回溯时:插入更新时:如当前节点的高度没有改变,则上面所有父节点的高度和平衡也不会改变。
删除更新时:如当前节点的高度没有改变且平衡值在 [-1, 1] 区间,则所有父节点的高度和平衡都不会改变。根据这两个推论,AVL 的插入和删除大部分时候只需要向上回溯一两个节点即可,范围十分紧凑。
谣言 4:虽然二者插入一万个节点总时间类似,但是 rbtree 树更平均,avl 有时很快,有时慢很多,rbtree 只需要旋转两次重新染色就行了,比 avl 平均完全说反了,avl 是公认的比 rbtree 平均的数据结构,插入时间更为平均,rbtree 才是不均衡,有时候直接插入就返回了(上面是黑色节点),有时候插入要染色几个节点但不旋转,有时候还要两次旋转再染色然后递归到父节点。该说法最大的问题是以为 rbtree 插入节点最坏情况是两次旋转加染色,可是忘记了一条,需要向父节点递归,比如:当前节点需要旋转两次重染色,然后递归到父节点再旋转两次重染色,再递归到父节点的父节点,直到满足 rbtree 的 5 个条件。这种说法直接把递归给搞忘记了,翻翻看 linux 的 rbtree 代码看看,再平衡时那一堆的 while 循环是在干嘛?不就是向父节点递归么?avl 和 rbtree 插入和删除的最坏情况都需要递归到根节点,都可能需要一路旋转上去,否则你设想下,假设你一直再树的最左边插入 1000 个新节点,每次都想再局部转两次染染色,而不去调整整棵树,不动根节点,可能么?只是说整个过程 avl 更加平均而已。
结论:AVL / RBTREE 真的差不多,AVL 被早期各种乱七八糟的实现和数学上的 “统计” 给害了,别盯着 linux 用了 rbtree 就觉得 rbtree 一定好过 avl 了,solaris 里面大范围的使用 avltree ,完全没有 rbtree 的痕迹那。—–更新:无图无真相,给一下我测试的编译器和标准库版本吧,否则疑惑我在和 vc6 做比较呢。主要开发环境:mingw gcc 5.2.0linux rbtree with 10000000 nodes: insert time: 4451ms, height=32 search time: 2037ms error=0 delete time: 548ms total: 7036ms avlmini with 10000000 nodes: insert time: 4563ms, height=27 search time: 2018ms error=0 delete time: 598ms total: 7179ms std::map with 10000000 nodes: insert time: 4281ms search time: 4124ms error=0 delete time: 767ms total: 9172ms linux rbtree with 1000000 nodes: insert time: 355ms, height=26 search time: 171ms error=0 delete time: 46ms total: 572ms avlmini with 1000000 nodes: insert time: 438ms, height=24 search time: 141ms error=0 delete time: 47ms total: 626ms std::map with 1000000 nodes: insert time: 345ms search time: 360ms error=0 delete time: 62ms total: 767ms又测试了一下 vs2017,结论类似:linux rbtree with 10000000 nodes: insert time: 4201ms, height=32 search time: 3411ms error=0 delete time: 567ms total: 8179ms avlmini with 10000000 nodes: insert time: 4250ms, height=27 search time: 3233ms error=0 delete time: 658ms total: 8141ms std::map with 10000000 nodes: insert time: 4658ms search time: 4275ms error=0 delete time: 815ms total: 9748ms linux rbtree with 1000000 nodes: insert time: 330ms, height=26 search time: 316ms error=0 delete time: 62ms total: 708ms avlmini with 1000000 nodes: insert time: 409ms, height=24 search time: 266ms error=0 delete time: 53ms total: 728ms std::map with 1000000 nodes: insert time: 426ms search time: 375ms error=0 delete time: 78ms total: 879ms注意,avlmini 和 linux rbtree 都是使用结构体内嵌的形式,这样和 std::map 这种需要 overhead 的容器比较起来 std::map 太吃亏了,所以我测试时,每次插入 avlmini 和 linux rbtree 之前都会模拟 std::map 为每对新的 (key, value) 分配一个结构体(包含 node 信息和 key, value),再插入,这样加入了内存分配的开销,才和 std::map 进行比较。参考:别人做的更多树和哈希表的评测 rcarbone/kudb

程序员柠檬
/***20210119 更新 *********\/没想到这个老回答这两天突然火了,那再来更新点干货吧!本职工作是某大厂的 C++ 后台开发,术业有专攻,文末分享经验,如何成为一名合格的 Linux 后台服务器开发程序员,并推荐书单!希望对大家有帮助~/*********************\/**以下正文我是自学数据结构,没有老师带着,刚接触数据结构中这么多关于「树的概念」的时候,也是一脸懵的状态。把书看完一遍之后,脑子里 AVL 树,红黑树,B 树,B + 树,Trie 树一团糟的状态~**先说数据结构数据结构这门课程是计算机相关专业的基础课,数据结构指的是数据在计算机中的存储、组织方式。我们在学习数据结构时候,会遇到各种各样的基础数据结构,比如堆栈、队列、数组、链表、树… 这些基本的数据结构类型有各自的特点,不同数据结构适用于解决不同场景下的问题。树形结构相比数组、链表、堆栈这些数据结构来说,稍微复杂一点点,但树形结构可以用于解决很多实际问题,因为现实世界事物之间的关系往往不是线性关联的,而「树」恰好适合描述这种非线性关系。今天就带大家一起学习下,数据结构中的各种「树」,这也是面试中经常考察的内容,手撕二叉树是常规套路,对候选人也很有区分度,看完我的这个回答,相信大家都会心中有「树」了。
从树说起什么是树?现实中的树大家都见过,在数据结构中也有树,此树非彼树,不过数据结构的树和现实中的树在形态上确实有点相像。树是非线性的数据结构,用来模拟具有树状结构性质的数据集合,它是由 n 个有限节点组成的具有层次关系的集合。在数据结构中树是非线性数据结构,那我们先来了解下,什么是线性与非线性数据结构?线性结构线性结构**是一个有序数据元素的集合。 其中数据元素之间的关系是一对一的关系,即除了第一个和最后一个数据元素之外,其它数据元素都是首尾相接的,常用的线性结构有:线性表,栈,队列,双端队列,数组,串。
可以想象,所谓的线性结构数据组织形式,就像一条线段一样笔直,元素之间首尾相接。比如现实中的火车进站、食堂打饭排队的队列。
非线性结构简而言之,线性结构的对立面就是非线性结构。树线性结构中节点是首位相接一对一关系,在树结构中节点之间不再是简单的一对一关系,而是较为复杂的一对多的关系,一个节点可以与多个节点发生关联,树是一种层次化的数据组织形式,树在现实中是可以找到例子的,比如现实中的族谱,亲戚之间的关系是层次关联的树形关系。数据结构中的「树」的名字由来,是因为如果把节点之间的关系直观展示出来,由于长得和现实世界中的树很像,由此得名。如图: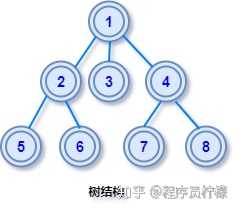
树的关键概念人们对树形结构的研究比较深入,为了方便研究树的各种性质,抽象出了一些树相关的概念,以便清晰简介的描述一颗树。下面几个基础概念必须了解,否则你当你刷 LeetCode 树相关题目时候,或者面试官向你描述问题时,你会连题目都看不懂事什么意思。先来上一个图解,下面的术语和概念对照着看,更容易理解。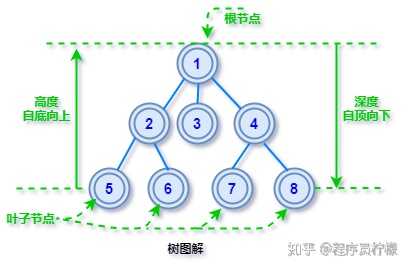
什么是节点的度?度很好理解,直观来说,数一下节点有几个分叉就说这个节点的度是多少。什么是根节点?在一颗树形结构中,最顶层的那个节点就是根节点了,所有的子节点都源自它发散开来。什么是父节点?树的父子关系和现实中很相似,若一个节点含有子节点,则这个节点称为其子节点的父节点。什么是叶子节点?直观来看叶子节点都位于树的最底层,就是没有分叉的节点,严格的定义是度为 0 的节点叫叶子节点。什么是节点的高度?高度是从叶子节点开始「自底向上」逐层累加的路径长度,树叶的高度为 0(有些书上也说是 0,不用纠结)什么是节点的深度?深度是从根节点开始「自顶向下」逐层累加的路径长度,根的深度为 1(有些书上也说是 0,问题不大)小技巧:高度和深度,一个从下往上数,一个从上往下数。树的特点树形数据结构,具有以下的结构特点:每个节点都只有有限个子节点或无子节点;没有父节点的节点称为根节点;每一个非根节点有且只有一个父节点;除了根节点外,每个子节点可以分为多个不相交的子树;树里面没有环路,意思就是从一个节点出发,除非往返,否则不能回到起点。二叉树有了前面「树」的基础铺垫,二叉树是一种特殊的树,还记的上面我们学过「节点的度」吗?二叉树中每个节点的度不大于 2 ,即它的每个节点最多只有两个分支,通常称二叉树节点的左右两个分支为左右子树。二叉树是很多其他树型结构的基础结构,比如下面要讲的 AVL 树、二叉查找树,他们都是由二叉树增加一些约束条件进化而来。三种遍历方式二叉树的遍历就是逐个访问二叉树节点的数据,常见的二叉树遍历方式有三种,分别是前中后序遍历,初学者分不清这几个顺序的差别。有个简单的记忆方式,这里的「前中后」都是对于根节点而言。先访问根节点后访问左右子树的遍历方式是前序遍历,先访问左右子树最后访问根节点的遍历方式是后序遍历,先访问左子树再访问根节点最后访问右子树的遍历方式是中序遍历,下面详细说明: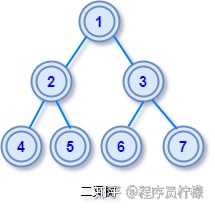
前序遍历遍历顺序是根节点 -> 左子树 -> 右子树遍历的得到的序列是:1 2 4 5 3 6 7中序遍历遍历顺序是左子树 -> 根节点 -> 右子树遍历的得到的序列是:4 2 5 1 6 3 7后序遍历遍历顺序是左子树 -> 右子树 -> 根节点遍历的得到的序列是:4 5 2 6 7 3 1二叉查找树由于最基础的二叉树节点是无序的,想象一下如果在二叉树中查找一个数据,最坏情况可能要要遍历整个二叉树,这样的查找效率是非常低下的。由于基础二叉树不利于数据的查找和插入,因此我们有必要对二叉树中的数据进行排序,所以就有了「二叉查找树」,可以说这种树是为了查找而生的二叉树,有时也称它为「二叉排序树」,都是同一种结构,只是换了个叫法。查找二叉树理解了也不难,简单来说就是二叉树上所有节点的,左子树上的节点都小于根节点,右子树上所有节点的值都大于根节点。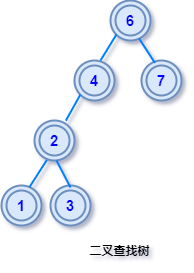
这样的结构设计,使得查找目标节点非常方便,可以通过关键字和当前节点的对比,很快就能知道目标节点在该节点的左子树还是右子树上,方便在树中搜索目标节点。如果对排序二叉树执行中序遍历,因为中序遍历的顺序是:左子树 -> 根节点 -> 右子树,最终可以得到一个节点值的有序列表。举个栗子:对上图的排序二叉树执行中序遍历,我们可以得到一个有序序列:1 2 3 4 5 6 7查询效率二叉查找树的查询复杂度取决于目标节点的深度,因此当节点的深度比较大时,最坏的查询效率是 O(n),其中 n 是树中的节点个数。实际应用中有很多改进版的二叉查找树,目的是尽可能使得每个节点的深度不要过深,从而提高查询效率。比如 AVL 树和红黑树,可以将最坏效率降低至 O(log n),下面我们就来看下这两种改进的二叉树。AVL 树AVL 也叫平衡二叉查找树。AVL 这个名字的由来,是它的两个发明者 G. M. Adelson-Velsky 和 Evgenii Landis 的缩写,AVL 最初是他们两人在 1962 年的论文「An algorithm for the organization of information」中提出来一种数据结构。定义AVL 树是一种平衡二叉查找树,二叉查找树我们已经知道,那平衡是什么意思呢?我们举个天平的例子,天平两端的重量要差不多才能平衡,否则就会出现向一边倾斜的情况。把这个概念迁移到二叉树中来,根节点看作是天平的中点,左子树的高度放在天平左边,右子树的高度放在天平右边,当左右子树的高度相差「不是特别多」,称为是平衡的二叉树。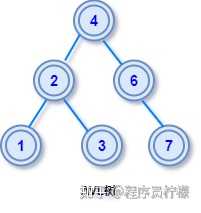
AVL 树有更严格的定义:在二叉查找树中,任一节点对应的两棵子树的最大高度差为 1,这样的二叉查找树称为平衡二叉树。其中左右子树的高度差也有个专业的叫法:平衡因子。AVL 树的旋转一旦由于插入或删除导致左右子树的高度差大于 1,此时就需要旋转某些节点调整树高度,使其再次达到平衡状态,这个过程称为旋转再平衡。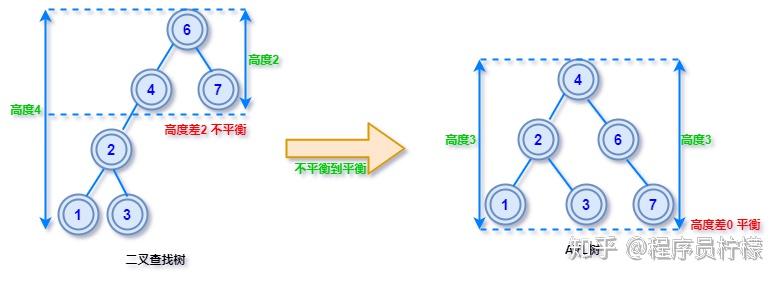
保持树平衡的目的是可以控制查找、插入和删除在平均和最坏情况下的时间复杂度都是 O(log n),相比普通二叉树最坏情况的时间复杂度是 O(n) ,AVL 树把最坏情况的复杂度控制在可接受范围,非常合适对算法执行时间敏感类的应用。B 树B 树是鲁道夫 · 拜尔(Rudolf Bayer)1972 年在波音研究实验室(Boeing Research Labs)工作时发明的,关于 B 树名字的由来至今是个未解之谜,有人猜是 Bayer 的首字母,也有人说是波音实验室(Boeing Research Labs)的 Boeing 首字母缩写,虽然 B 树这个名字来源扑朔迷离,我们心里也没点 B 树,但不影响今天我们来学习它。定义一个 m 阶的 B 树是一个有以下属性的树每一个节点最多有 m 个子节点每一个非叶子节点(除根节点)最少有 ⌈m/2⌉ 个子节点,⌈m/2⌉表示向上取整。如果根节点不是叶子节点,那么它至少有两个子节点有 k 个子节点的非叶子节点拥有 k − 1 个键所有的叶子节点都在同一层如果之前不了解,相信第一眼看完定义肯定是蒙圈,不过多看几遍好好理解一下就好了,画个图例,对照着看看: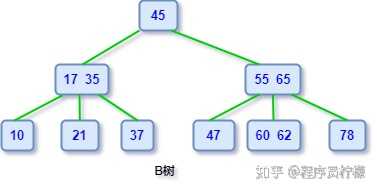
特点B 树是所有节点的平衡因子均等于 0 的多路查找树(AVL 树是平衡因子不大于 1 的二路查找树)。B 树节点可以保存多个数据,使得 B 树可以不用像 AVL 树那样为了保持平衡频繁的旋转节点。B 树的多路的特性,降低了树的高度,所以 B 树相比于平衡二叉树显得矮胖很多。B 树非常适合保存在磁盘中的数据读取,因为每次读取都会有一次磁盘 IO,高度降低减少了磁盘 IO 的次数。B 树常用于实现数据库索引,典型的实现,MongoDB 索引用 B 树实现,MySQL 的 Innodb 存储引擎用 B + 树存放索引。说到 B 树不得不提起它的好兄弟 B + 树,不过这里不展开细说,只需知道,B + 树是对 B 树的改进,数据都放在叶子节点,非叶子节点只存数据索引。红黑树红黑树也是一种特殊的「二叉查找树」。到目前为止我们学习的 AVL 树和即将学习的红黑树都是二叉查找树的变体,可见二叉查找树真的是非常重要基础二叉树,如果忘了它的定义可以先回头看看。特点红黑树中每个结点都被标记了红黑属性,红黑树除了有普通的「二叉查找树」特性之外,还有以下的特征:节点是红色或黑色。根是黑色。所有叶子都是黑色(叶子是 NIL 节点)。每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。这些性质有兴趣可以自行研究,不过,现在你只需要知道,这些约束确保了红黑树的关键特性:从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。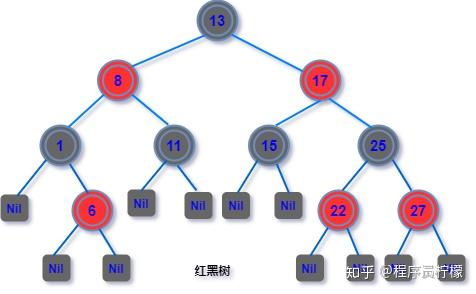
而节点的路径长度决定着对节点的查询效率,这样我们确保了,最坏情况下的查找、插入、删除操作的时间复杂度不超过 O(log n),并且有较高的插入和删除效率。应用场景红黑树在实际应用中比较广泛,有很多已经落地的实践,比如学习 C++ 的同学都知道会接触到 STL 标准库,而 STL 容器中的 map、set、multiset、multimap 底层实现都是基于红黑树。再比如,Linux 内核中也有红黑树的实现,Linux 系统在实现 EXT3 文件系统、虚拟内存管理系统,都有使用到红黑树这种数据结构。Linux 内核中的红黑树定义在内核文件如下的位置:
如果找不到,可以 find / -name rbtree.h 搜索一下即可,有兴趣可以打开文件看下具体实现。红黑树 VS 平衡二叉树(AVL 树)插入和删除操作,一般认为红黑树的删除和插入会比 AVL 树更快。因为,红黑树不像 AVL 树那样严格的要求平衡因子小于等于 1,这就减少了为了达到平衡而进行的旋转操作次数,可以说是牺牲严格平衡性来换取更快的插入和删除时间。红黑树不要求有不严格的平衡性控制,但是红黑树的特点,使得任何不平衡都会在三次旋转之内解决。而 AVL 树如果不平衡,并不会控制旋转操作次数,旋转直到平衡为止。查找操作,AVL 树的效率更高。因为 AVL 树设计比红黑树更加平衡,不会出现平衡因子超过 1 的情况,减少了树的平均搜索长度。Trie 树(前缀树或字典树)Trie 来源于单词 retrieve(检索),Trie 树也称为前缀树或字典树。利用字符串前缀来查找指定的字符串,缩短查找时间提高查询效率,主要用于字符串的快速查找和匹配。为什么要称其为字典树呢?因为 Trie 树的功能就像字典一样,想象一下查英文字典,我们会根据首字母找到对应的页码,接着根据第二、第三… 个单词,逐步查找到目标单词,Trie 树的组织思想和字典组织很像,字典树由此得名。
定义Trie 的核心思想是空间换时间,有 3 个基本性质:根节点不包含字符,除根节点外每一个节点都只包含一个字符。从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。每个节点的所有子节点包含的字符都不相同。比如对单词序列lru, lua, mem, mcu 建立 Trie 树如下: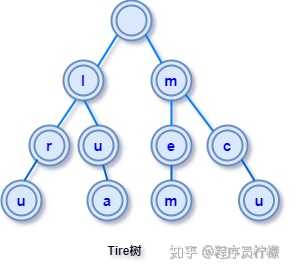
Trie 树建立和查询是可以同步进行的,可以在还没建立出完成的 Trie 树之前就找到目标数据,而如果用 Hash 表等结构存储是需要先建立完成表才能开始查询,这也是 Trie 树查询速度快的原因。应用Trie 树还用于搜索引擎的关键词提示功能。比如当你在搜索框中输入检索单词的开头几个字,搜索引擎就可以自动联想匹配到可能的词组出来,这正是 Trie 树的最直接应用。
这种结构在海量数据查询上很有优势,因为不必为了找到目标数据遍历整个数据集合,只需按前缀遍历匹配的路径即可找到目标数据。因此,Trie 树还可用于解决类似以下的面试题:给你 100000 个长度不超过 10 的单词。对于每一个单词,我们要判断他出没出现过,如果出现了,求第一次出现在第几个位置。
有一个 1G 大小的一个文件,里面每一行是一个词,词的大小不超过 16 字节,内存限制大小是 1M,求频数最高的 100 个词
1000 万字符串,其中有些是重复的,需要把重复的全部去掉,保留没有重复的字符串,请问怎么设计和实现?
一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前 10 个词,请给出思想,给出时间复杂度分析。总结一下树形数据结构有许多变种,这篇文章我们从树开始,把几种常见树形数据结构学习了一遍,包括二叉树、二叉查找树(二叉搜索树)、AVL 树、红黑树、B 树、Trie 树。,因为数据结构中各种树的变体非常多,一篇文章实难细数,篇幅有限,也只能说是浅尝辄止,作为树形数据结构入门,如果要深入的学习,每个知识点还能写出一篇文章,比如 B+ 树原理及其在数据库索引中的应用、红黑树的详细分析等等,这次柠檬只是粗略带大家走一遍。在后端开发中,数据结构与算法是后端程序员的基本素养,除了基础架构部的后端开发同学,虽然我们平常不会经常造轮子,但是掌握基本的数据结构与算法仍然是非常有必要,面试也对相关能力有要求。学习算法和数据结构不仅能提高自身编程能力,关键是现在大厂面试几乎都要让你写几道算法题,我找到一本谷歌大神的 LeetCode 刷题笔记,总结出算法刷题套路、条理清晰,BAT 刷题必备:https://zhuanlan.zhihu.com/p/336587820zhuanlan.zhihu.com 说了这么多,其实最务实的学习方式是读书!从事软件行业这么些年,开始也有迷茫不知方向,也不懂要看啥书学些什么内容,为了避免这样的问题,我整理了程序员进阶书单,让你少走些弯路。月薪 30K 的程序员都学啥?附书单mp.weixin.qq.com我目前的工作是某大厂 C++ 后台开发,术业有专攻,如果你看到这,一定要看下我这篇 1 万 5 千字的后端开发完全学习指南,一定让你有收获!后端都要学习什么?www.zhihu.com
说了这么多,其实最务实的学习方式是读书!从事软件行业这么些年,开始也有迷茫不知方向,也不懂要看啥书学些什么内容,为了避免这样的问题,我整理了程序员进阶书单,让你少走些弯路。月薪 30K 的程序员都学啥?附书单mp.weixin.qq.com我目前的工作是某大厂 C++ 后台开发,术业有专攻,如果你看到这,一定要看下我这篇 1 万 5 千字的后端开发完全学习指南,一定让你有收获!后端都要学习什么?www.zhihu.com 说到 C++ 的话,我长期在知乎分享 C++ 学习相关,有些经验分享,你看下对你是否有用,有帮助的话点个赞同呗(疯狂暗示哈哈)C++ 研发实习生面试通常会被问到什么问题?www.zhihu.com
说到 C++ 的话,我长期在知乎分享 C++ 学习相关,有些经验分享,你看下对你是否有用,有帮助的话点个赞同呗(疯狂暗示哈哈)C++ 研发实习生面试通常会被问到什么问题?www.zhihu.com Visual Studio Code 如何编写运行 C、C++ 程序?www.zhihu.com
Visual Studio Code 如何编写运行 C、C++ 程序?www.zhihu.com 寒假 45 天如何自学入门 C++?www.zhihu.com
寒假 45 天如何自学入门 C++?www.zhihu.com 用一年时间如何能掌握 C++ ?www.zhihu.com
用一年时间如何能掌握 C++ ?www.zhihu.com 能不能推荐几本 c++ 的书?www.zhihu.com
能不能推荐几本 c++ 的书?www.zhihu.com 更多干货文章,关注我的专栏:学编程,涨工资www.zhihu.com
更多干货文章,关注我的专栏:学编程,涨工资www.zhihu.com /**20210307 更新 ***金三银四跳槽面试季,整理了 68 个 C++ 常见面试题,希望对看到这篇文章的同学有帮助,offer 拿到手软!https://zhuanlan.zhihu.com/p/346821046zhuanlan.zhihu.com
/**20210307 更新 ***金三银四跳槽面试季,整理了 68 个 C++ 常见面试题,希望对看到这篇文章的同学有帮助,offer 拿到手软!https://zhuanlan.zhihu.com/p/346821046zhuanlan.zhihu.com 我是@程序员柠檬关注我,学习更多编程知识!
我是@程序员柠檬关注我,学习更多编程知识!
/****20210122 更新** ***/
收藏 900+ 点赞 300+
原创分享,码字不易,如果回答对你有帮助,各位在收藏之前点个赞同感谢,或分享给更多需要的小伙伴呗~

郁白
已有的几个答案都是从算法角度分析的,我尝试分析下从工程角度区分红黑树与 b + 树的应用场景,红黑树一个 node 只存一对 kv,因此可以使用类似嵌入式链表的方式实现,数据结构本身不管理内存,比较轻量级,使用更灵活也更省内存,比如一个 node 可以同时存在若干个树或链表中,内核中比较常见。而 b + 树由于每个 node 要存多对 kv,node 结构的内存一般就要由数据结构自己来管,是真正意义上的 container,相对嵌入式方法实现的红黑树,好处是用法简单,自己管理内存更容易做 lockfree,一个 node 存多对 kv 的方式 cpu cache 命中率更高,所以用户态实现的高并发索引一般还是选 b + 树。再说 b 树与 b + 树,btree 的中间节点比 b + 树多存了 value,同样出度的情况下,node 更大,相对来说 cpu cache 命中率是不如 b + 树的。另外再提一句,b + 树的扫描特性(链表串起来的叶子节点)在无锁情况下是很难做的(我还没见到过解法),因此我目前见到的无锁 b + 树叶子节点都是不串起来的。补充下,关于相同前缀的优化存储和优化查询 b + 树也可以做的。
